In this chapter, we review some related efforts in the research and development of workflow description languages and workflow schedulers in the area of grid and distributed computing. Based on our study, we motivate our work to develop an advanced scheduling system for grid scientific workflow applications.
There have been a large number of efforts to develop a workflow description language to support different types of workflow in different application area. In this section, we review those that are relevant to grid computing and web service architecture.
Condor [67] is a resource management system for distributed computing resources, such as clusters of PCs, and the Directed Acyclic Graph Manager (DAGMan) [8] is the workflow scheduler in Condor. DAGMan uses DAG as the data structure to represent job dependencies, and a data flow is specified by a parent-child relationship. The following code fragment is the Condor DAG specification of a diamond workflow. Condor does not support for specifying intermediate files between tasks, and users have to specify data transfer through the preprocessing and postprocessing script associated with each job. DAGMan supports partial workflow execution in the workflow description files. If a job is marked as DONE, then this job is not scheduled.
The Chimera Virtual Data System (VDS) [68] is a set of tools for data-processing workflow management, including expressing, executing, and tracking the results of workflows. The workflow description language of Chimera is called Virtual Data Language (VDL), and it is a data-flow style language. In VDL, a set of application programs are described as transformations (TR) and the executions of transformations are described as derivations (DV). Derivations produce or consume data files, which are described as data objects. The following code fragment is an example of a VDL transformation, one of its derivation and a data processing job. We refer interested readers to [69] for the syntax details. In Chimera, VDL definitions are stored in a catalog that provides for the tracking of the provenance of all files derived by an application. Chimera VDS contains the recipe to produce a given logical file, and the dependencies between derivations in terms of these data files constitutes the application abstract workflow in the form of a DAG of program execution steps.
Taverna [9] is a workflow environment for grid life-science applications. Taverna uses an extended Scufl [70], XScufl, as the workflow description language. The Scufl language is essentially a data-flow centric language. In Scufl, a logical service, an individual step within a workflow, is called processor, which can be regarded as a function of some set of input data to a set of output data. A set of data links connect data source processors to data destination processors. Taverna developed a set of processor plug-ins that handle the data flow on data links, for example, A WSDL Scufl processor implemented by a single Web Service operation described in a WSDL. The fields of the Web Service operation request message correspond to the input ports and the fields of the return message to the output ports.
ASKALON and Karajan workflow systems both define a control-flow style language to describe application logics [71, 10]. In this style, the task execution order, which is implied by task dependency relationships, is explicitly specified using sequential and parallel syntax. For example, for the diamond workflow we used before, the specification could be “{sequential A, {parallel B, C}, D}”. It is read: task A, task group {parallel B, C} and task D must be executed in sequential order, where tasks B and C can be executed concurrently. In this way, the dependency relationships between tasks are implicitly constrained by the task execution order that is specified by using the two syntactics. In addition to these two, ASKALON and Karajan introduce other imperative programming structures, such as for, if, switch, etc., to specify complex control-flow logics. Karajan also allows the definition and use of variables and functions in the specification.
Triana [11] provides a graphical environment to enable the composition of workflow applications through mouse input. In the Triana workflow language, a component, the unit of execution, is a Java class with an identifying name, input and output “ports”, a number of optional name/value parameters and a single process method. Triana uses both data-flow and control-flow in workflow description. In the case of data-flow, data arriving on the input “port” of the component triggers execution, and in the case of control-flow, a control command triggers the execution of the component. The execution of workflow within Triana is decentralized; data or control flow “messages” are sent along communication “pipes” from sender to receiver.
<tool>
<name>Tangent</name> <description>Tangent of the input data</description> <inportnum>1</inportnum> <outportnum>1</outportnum> <input> <type>triana.types.GraphType</type> <type>triana.types.Const</type> </input> <output>...</output> <parameters> <param name="normPhaseReal" value="0.0" type="userAccessible"/> <param name="normPhaseImag" value="0.0" type="userAccessible"/> <param name="toolVersion" value="3" type="internal"/> </parameters> </tool> |
YAWL [72] is a workflow language built upon two main concepts: workflow patterns and Petri Nets [64]. It was developed by taking Petri Nets as a starting point and adding mechanisms to allow for more direct and intuitive support of different workflow patterns. Similar to the Karajan and ASKALON approach, it is a control-flow style language.
Business Process Execution Language (BPEL) [73] is an XML-based workflow definition language to describe enterprise business processes in web services. In BPEL, a workflow step is described using WSDL. For scientific applications, either extensions to the language or the wrapping of the applications is needed to use BPEL.
Semantics web [74] standards, Resource Description Framework (RDF) [75] and Web Ontology Language (OWL) [76], aim to provide another structuring and description framework that allows data to be integrated in a much larger-scale than what current HTML-framework provides. The general-purpose semantic web standards are very abstract and additional vocabularies need to be defined for a specific field.
Most existing workflow description languages focus on being expressive enough to describe the data flow and control flow of workflow structures. They lack the features for users to provide resource request information to support resource allocations for workflow tasks by the scheduler. For example, the resource request information for multiple dependent tasks could be specified to support workflow-orchestrated resource co-allocation and execution planning. One workaround is to make the resource multi-request using another method, such as RSL [77] that is independent of the workflow description. However, users have to derive the resource multi-request from the workflow task relationships, and the derivation is a complex reasoning process. The workflow scheduler has to refer to two specifications, one for resource allocation and one for workflow scheduling, which complicates its decision making process during resource allocation and scheduling.
Aside from scheduling support, a workflow language should provide ease of use and should support workflows with a plethora of different requirements. Some typical features include helping handle errors produced before, during and after task executions and dependency handling, support for partial workflow specification, and support for application-specific utilities for task launching, termination and restarting. We have found that these features are not, or are only partially supported in the workflow language development efforts.
In most workflow systems, such as DAGMan [8], Taverna [9], Karajan [10], Kepler [78] and Triana [11], the fundamental mechanism of the workflow scheduling is to perform breadth-first traversal of the workflow structure and then launch workflow tasks based on the traversal order. They do not have resource allocation capability and resource information for workflow tasks are specified in the workflow description. Thus, they are not the focus of our study. In the rest of this section, we review those efforts that have advanced workflow scheduling and resource allocation capabilities.
The ASKALON workflow scheduler [71, 79] provides three algorithms for workflow application scheduling: Heterogeneous Earliest Finish Time (HEFT), a genetic algorithm, and a just-in-time algorithm acting like a resource broker. In the HEFT algorithm, the scheduler considers allocating a resource to a workflow task that can complete the task the fastest. The genetic algorithm is a look-ahead scheduling one that applies techniques, such as performance prediction, workflow partition and resource reservation, in the workflow resource allocation and execution planning process. When dealing with control flow in which some dependencies can only be determined at run time, the algorithm makes assumptions about whether to handle the dependency or not in scheduling. Incorrect assumptions are resolved by appropriate run-time adjustments such as undoing existing optimizations and rescheduling. But in the performance evaluation of these algorithms, ASKALON made several assumptions that are unrealistic in computational grid environments. For example, it assumes a resource is allocated upon request, thus the grid scheduling hierarchy issue is skipped.
Gridbus workflow scheduler [14, 80] applies a look-ahead and budget/deadline-driven workflow scheduling algorithm. A workflow submitted by a user for execution has costs associated with each task and the user also specifies a budget and a deadline that must be met. The algorithm partitions the workflow into subworkflows, each of which has a budget and a deadline. As along as the budgets and deadlines of all the subworkflows are met, the budget and the deadline of the workflow are met. But this algorithm targets a utility grid that assumes a service level agreement between service provider and service consumer, which implies that there is no queue waiting in the workflow execution, neither the impact of resource load on the workflow performance. For computational grid environments with a grid scheduling hierarchy, these implications are not applicable.
Pegasus [13] is the Chimera workflow manger that takes the abstract workflow and constructs a job execution DAG with scheduling information from the application DAG logic. This process includes querying Globus MDS to find resources for computation and data movement, and querying a Globus replica location service to locate data replicas. It finally produces a concrete workflow conforming Condor DAG specification, and submits the specification to DAGMan for execution. Other than suffering the same limitation of Condor DAG, it is also not allowed to specify resource request information to aid the Pegasus resource allocation process.
In GridFlow [81], a workflow is executed according to a simulated schedule. If large delays occur in sub-workflows, the rest or all of the workflow may be sent back to the simulation engine and rescheduled. The concept of a simulated schedule is similar to the execution plan or schedule. But GridFlow does not address resource co-allocation and reservation issues in the simulated schedule.
There are also many systems that address specific issues of grid co-scheduling. Globus GRAM [39] and RSL [77] are the early, de-facto standards for providing solutions for secure job execution in metacomputing environments. DUROC [82] is an early effort to address the issues of resource co-allocation in the context of Globus and RSL. Globus GARA [40], Maui Silver [83] and the architecture defined in [84] introduce advanced reservation into the GRAM co-allocation architecture [85]. SNAP [86], which extends Globus’ GRAM and GARA, proposes a service negotiation protocol for grid scheduling.
The K-Grid scheduler [87] is a performance-oriented resource allocation service for knowledge discovery and data mining applications. It predicts the computational and I/O cost for each allocation and makes the best-possible decisions based on this estimation. But the K-Grid scheduler does not reserve resources for applications and relies on the grid resource discovery services to find the best available resources.
The Community Scheduler Framework (CSF) [88] implements a set of grid services which provide basic capabilities for grid job submission and resource reservation. These services, developed as wrappers for some local scheduler utilities, provide a good starting point to develop a brokerage system. But CSF services only cater for single executable jobs and lack functionalities for grid co-scheduling.
Maui Silver [83] is an advanced reservation-based grid scheduler which allows a single job to be scheduled across distributed clusters. Silver relies on the local scheduler to specify and coordinate the job workflow, which limits it usage to simple workflow applications.
Nimrod/G [89] is a resource management system with a focus on computational economy and schedules tasks based on their deadlines and budgets. Nimrod/G also addresses issues of scheduling single jobs, and does not address the requirements of workflow applications.
MARS [90] proposes an on-demand scheduler which discovers and schedules the required resources for a critical-priority task to start immediately. MARS uses a forecasting strategy to predict runtime resource parameters, such as queue lengths, utilization, etc.
Based on our study, we found there are mainly two types of schedulers, application-level schedulers and system-level schedulers. An application-level scheduler [91] manages the execution of a single application and improves the performance of the application by utilizing the available resources. A system-level scheduler, often termed as a resource manager, manages all the applications and resources of a system with goals to improve the overall system utilization and load balancing. An application-level scheduler works on top of one or multiple system-level schedulers, and has to coordinate with the system-level schedulers to utilize the resources. So the development of an application-level scheduler must take into account the existence of system-level schedulers, and the scheduling policies and issues in the underlying system-level schedulers. In our context, the workflow scheduler is an application-scheduler and the local scheduler is a system-level scheduler.
However, in reviewing those related efforts, we have found that the system-level scheduling and grid resource management issues have not been taken into enough account in the workflow scheduler development. As a result, when evaluating workflow scheduling algorithms, the assumptions made are unrealistic for real computational grid environments. For example, they assume that a resource is allocated upon request or a reservation is always granted upon request. Those assumptions are not unreasonable for a dedicated grid environment with low resource load and that guarantees resource availability and high network bandwidth. But in a grid that includes resources linked by the unreliable Internet and used for a variety of grid applications, the data transfer, resource load and queue waiting contribute significantly and negatively to the workflow execution performance. So those assumptions do not apply in those grid environments. As a result, the scheduler developed may not adapt to real and dynamic computational grid environments.
On the other hand, we have noticed that the efforts to develop a general purpose grid scheduler provide solutions to the grid resource management issues, such as resource co-allocation, performance prediction and resource reservation. But most of those solutions are developed and used in a system-level scheduler and very few efforts study and use those techniques in grid workflow systems. We believe, if applied in a workflow scheduler, those advanced scheduling techniques can greatly improve the overall workflow execution performance.
To apply those techniques into the workflow scheduling process, an extensible workflow system architecture is required to integrate those techniques into the workflow scheduler. Most of current workflow schedulers are developed as integrated softwares to provide the functionalities of resource allocations, scheduling, dependency handling and run time coordinations. As a result, the additions and/or plug-ins of new features to the workflow system require either the redesign or extensively patch work. This approach results in an inextensible and unmodularized system software that is hard for further integrations.
Based on our discussion of the related works to develop workflow description languages and workflow schedulers, we summarize several issues in the following aspects that are not well addressed in current efforts in order to provide support for automatic execution of workflow applications in computational grid environments:
Driven by the needs of workflow application support in grid environments, the GRACCE (Grid Application Coordination, Collaboration and Execution) project [92] was proposed to address the requirements above. The vision of GRACCE is to provide domain scientists with an integration framework for building a customizable grid application environment, from the management of a workflow application and its dataset, to the automatic execution and viewing of results. In the GRACCE framework, end users are only required to provide descriptions of their workflow applications. GRACCE is responsible for allocating grid resources to workflow tasks, placing tasks on resources for execution, monitoring them, and returning the results back to users as desired. More specifically, the solutions provided by the GRACCE framework to address those requirements are as follows:
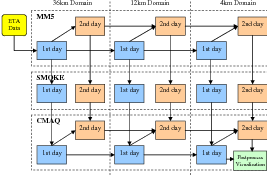
One workflow application that we have been working on, the Air Quality Forecasting (AQF) [93], is the original motivation of our GRACCE framework. AQF application is an integrated computational model for regional and local air quality forecasts, and is composed of three subsystems: the PSU/NCAR MM5 weather forecast model, the SMOKE emission system, and EPA’s CMAQ chemical transport model. An AQF execution is a computational sequence of the three subsystems with increasing resolution and decreasing geographical boundaries. Figure 4.1 illustrates the workflow of a nested 2-day forecasting operation over a single region of interest by a three-domain computation. The 36km domain computation provides coarse forecast data over the continental USA, the 12km domain provides data across the south central USA, and the 4km domain forecasts air quality across a smaller geographic region.
AQF application represents most of current grid workflow applications and has the same requirements for grid middlewares if deployed in grid environments. The original design of the GRACCE framework is the result of the collaboration work between AQF users and us during the process of enabling AQF on the UH campus grid [94, 95, 93, 96]. So although targeting AQF application at the beginning, the GRACCE framework provides a set of middlewares for the deployment, integration and execution of grid scientific workflow applications.