|
In this chapter, we introduce the grid computing model, grid architecture and discuss the resource management issues in grid environments.
A new computing model is driven by the emerging applications, and is evolved or revolved from available computing models that are incapable to meet the requirements of these applications. The grid computing model follows this pattern: the foundation computing models are distributed computing and high performance computing; and the applications are “Big Science” applications [15].
Distributed computing represents a decentralized computing model using two or more computers communicating over a network to accomplish a common objective. The types of hardware, programming languages, operating systems and other resources of these computers may vary drastically. Distributing computing model ranges from loosely-coupled computing networks to tightly-integrated computing element pools for domain-specific applications. Distributed computing technology, such as client/server architecture [16] and CORBA [17], are widely used in enterprise applications, for example, web servers. One fundamental issue in distributed computing that is familiar to most of the computer users is to provide secure and transparent accesses to remote resources. The Transport Layer Security (TLS) and Secure Sockets Layer (SSL) [18], and the secure shell (SSH) [19], which provide secure communication protocol and local execution environment of remote machines, are the widely used and standard solution to this issue.
High performance computing (HPC) refers to the use of (parallel) supercomputers or computer clusters, computing systems linked together with commercially available interconnects, to solve large-scale science and engineering problems. Most of these applications are developed with Message Passing Interface (MPI) [20] or OpenMP [21] to exploit the parallel processing power of such systems. An HPC system normally has a batch scheduler, such as SGE [22], LSF [23] or PBS [24], installed to schedule user submitted jobs and to manage the parallel computing resources. The 500 most powerful publicly-known supercomputers in the world are listed in the TOP500 project [25], with update every 6 months.
After World War II, the style of scientific research developed defines the organization and character of much research in physics and astronomy and later in the biological sciences, and they are referred to as “Big Science” [26]. Big Science is characterized by the use of large-scale instruments and supercomputing facilities, and by involving scientists from multiple organizations. Some of the best-known Big Science projects include the high-energy physics facility CERN [27], the Hubble Space Telescope [28], and the Apollo program [29]. Big Science requires big computers, or supercomputers that are fundamentally different from personal computers in their ability to model enormous systems. Most of the supercomputers listed in TOP500 are built to solve such problems.
The popularity of the Internet and the World Wide Web [30] enables the direct remote resource access and the instantaneous information sharing around the globe. In a science research project, individuals across the world share information through WWW and emails in a similar way to organization-level collaborations. Researchers access remote computing resources and launch computational jobs through a secure and remote shell [19]. The science problems are globalized: individuals and resources from geographically distributed organizations can collaboratively work together without knowing each other.
The level of information sharing via Internet/WWW in the collaboration to solve the Big Science problems is mainly by file exchanging using FTP, HTTP, or email; and the mostly used approach to access computing resource is by individual’s remote secure shell. Such sharing and resource access pattern cannot fully achieve the close collaboration at the organization level of real world. Consider this situation, excerpted from an article – “Big Computer for Big Science” [31]: A visiting neutron scattering scientist at ORNL sends data from her experiment to a supercomputer at SDSC for analysis. The calculation results are sent to Argonne National Laboratory, where they are turned into “pictures”. These visualizations are sent to a collaborating scientist’s workstation at North Carolina State University, one of the core universities of UT-Battelle, which manages ORNL for DOE.
To make their discoveries in this situation, scientists must interact with supercomputers to generate, examine, and archive huge datasets. To turn data into insight, this interaction must occur on human time scales, i.e., over minutes. But using the conventional resource sharing approach, multiple asynchronous mail exchange, manual or script-based file transfer and remote resource access are involved, and they occur in days or even weeks. Such a situation is very common in the globalized Big Science research and the Internet age; and the real and specific problem that underlies the situation is
“the coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations. The sharing is not primarily file exchange but rather direct access to computers, software, data, and other resources, as is required by a range of collaborative problem-solving and resource brokering strategies emerging in industry, science, and engineering. This sharing is, necessarily, highly controlled, with resource providers and consumers defining clearly and carefully just what is shared, who is allowed to share, and the conditions under which sharing occurs.” [32]
This is the well-known “Grid Problem” and grid computing is the emerging computing model to solve this problem. Grid computing enables the sharing, selection, and aggregation of a wide variety of resources including supercomputers, storage systems, data sources, and specialized devices that are geographically distributed and owned by different organizations for solving large-scale computational and data intensive problems in science, engineering, and commerce. A grid can be viewed as a seamless, integrated computational and collaborative environment, which is often referred to as a “grid cyberinfrastructure” [33].
By modeling a virtual computer architecture from many distributed computers that is able to distribute process execution across these computers, grids provide the ability to perform computations on large data sets, by breaking them down into many smaller ones, or provide the ability to perform many more computations at once that would be possible on a single computer. So a grid can be viewed as a distributed supercomputer system; the grid resources are geographically distributed and connected via Internet, and it is presented to users as a single high-performance (virtual) computer system. A user will have access to the virtual computer that is reliable and adaptable to her needs, and the individual resources will not be visible to her.
Grid computing has been defined by different people in different literatures. The widely accepted two definitions, by the pioneers of grid computing, Ian Foster (also known as the father of grid computing), Carl Kesselman and Steve Tuecke are as follows:
A computational grid is a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to high-end computational capabilities. [1]
Grid computing is concerned with “coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations.” The key concept is the ability to negotiate resource-sharing arrangements among a set of participating parties (providers and consumers) and then to use the resulting resource pool for some purpose. [32]
The concept of grid computing started as a project to link geographically dispersed supercomputers [34], but now it has grown far beyond its original intent. The grid infrastructure can benefit many applications, including collaborative engineering, data exploration, high-throughput computing, and distributed supercomputing. In [35, 36], some major grid applications, deployed grid environments and research/development projects are collected. According to the applications a grid is targeted, current grid infrastructures are classified into different categories and in [1], those categories are discussed in details. In the following, the two most common categories are introduced:
The computational grid category denotes systems that integrate distributed high performance computing systems to provide higher computational capacity than the capacity of any constituent machine in the system. A grid in this category provides the aggregated resources to tackle problems that cannot be solved on a single system. Typically, applications that require distributed supercomputing are grand challenge problems such as weather forecasting or physics experiments.
The data grid category is for systems that provide an infrastructure for data and information processing and mining from data repositories that are distributed in a wide area network. It is specialized in providing an infrastructure of storage management and data access, replication, meta-data management and domain information retrieval. Target applications have datasets that approach or exceed a petabyte in size and involve data producing and consuming elements that are not just computing systems and human users, for example, a physics experiment collider.
The vision of grid computing is to create virtual dynamic organizations through secure, coordinated resource-sharing among individuals, institutions, and resources. The realization of this vision requires the (re-)definition of and the solutions to the issues in distributed and high performance computing fields. A grid architecture is also required to identify fundamental system components, to specify the purpose and function of these components, and to indicate how these components interact with one another [32].
Grid computing is a highly collaborative distributed computing model; solutions to traditional distributed computing issues, such as security and resource management, do not scale well in grid computing. Furthermore, grid computing introduces other issues, such as information services and data management. We summarize those grid issues in the following and refer readers to [37] or related literature for more detailed discussions.
Security: Most distributed computing systems use identity-based authentication and authorization control. As the typical case, a user is given a username and password for accessing a computing system; when she is ready to launch her applications, she logs into the system and submits the application jobs. In a grid environment, users or their agents simultaneously need accesses to multiple resources from different administrative domains that have different security mechanisms. This requirement creates several security issues [38]. The two typical ones are:
Single sign-on: A user should be able to authenticate once (e.g., when starting a computation) and initiate computations that acquire resources, use resources, release resources, and communicate internally, without further authentication of the user.
Interoperability with local security solutions: While the grid security solutions may provide inter-domain access mechanisms, an access to a resource will typically be determined by a local security policy that is enforced by local security mechanisms. It is impractical to modify every local resource to accommodate inter-domain accesses.
Resource Management: Grid resources are from different administrative domains that have their own local resource managers and a grid does not have full control of these resources. When managing these resources, a grid resource management system should respect the usage policies enforced by local resource managers, and meanwhile, deliver user required quality of services and improve global resource usage. This dilemma, i.e., managing a resource without ownership, is referred to as “site autonomy” and “heterogeneous substrate” issues [39]. Another requirement for grid resource management comes from the fact that some grid applications, such as workflow, require resources to be allocated based on the application execution patterns and coordinated allocations of multiple resources simultaneously are necessary in order to deliver application-level quality of services. Also, resource management should be able to adapt application requirements to resource availability, particularly, when the requirements and resource characteristics change during execution. These issues are referred to as resource co-allocation and online-control [40].
Information Services: Information services play an important role in grids [41]. They indicate the status and availability of grid entities, i.e., compute resources, software libraries, networks, etc., without which there would be little coordination in such a dynamic environment as a grid. A grid information system should provide two types of services, the accounting service and the auditing service. Grid accounting maintains historical information of resource status and job resource consumption for the purpose of performance prediction, resource allotment, charging and application performance tuning. Grid auditing provides runtime information of resource load status and application resource consumption for the purpose of resource allocation and resource usage control.
Data Management: Data-intensive, high-performance computing applications require the efficient management and transfer of terabytes or petabytes of information in wide-area, distributed computing environments. Data management is concerned with how to provide secure, efficient and transparent access to distributed, heterogeneous pools of data on wide-area grid resources [42]. In providing such services, grids should harness data, storage, and network resources located in distinct administrative domains, respect local and global policies governing how data can be used, schedule resources efficiently (again subject to local and global constraints), and provide high speed and reliable accesses to data.
Standardization: Grid computing is a highly integrated system and a grid is built from multi-purpose protocols and interfaces that address those fundamental issues described above. The grid vision requires protocols (and interfaces and policies) that are not only open and general-purpose but also standard. It is standards that allow to establish resource sharing arrangements dynamically with any interested party and thus to create something more than a plethora of balkanized, incompatible, non-interoperable distributed systems [43].
“Any software problem can be solved by adding another layer of indirection.”
— Steven M. Bellovin
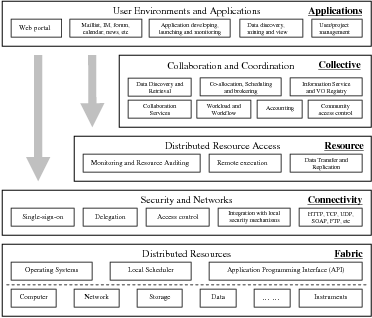
The general solutions to most of the grid issues are to aggregate the diversity and heterogeneousness of grid resources to create a uniform interface. The approach to such solutions falls into the “indirection” strategy above, that is, a layer-up architecture to hide and redirect those issues described before by developing a standard interface. We present the grid layered architecture in Figure 2.1, which is an extension of the architecture described in the grid anatomy paper [32], and it is similar to the one presented in [44]. This architecture is not implemented as a fully-integrated giant software; instead it integrates software utilities and tools that are already deployed or are being developed to solve specific issues. These utilities and tools are often referred to as “grid middleware”. Most current efforts in grid research and development provide middleware solutions to the issues included in this architecture.
In Figure 2.1, the bottom “Fabric” layer represents different distributed resources from different administrative domains, such as supercomputers or parallel computing clusters, storage systems, scientific instruments and data resources. Those resources are managed by domain-specific resource managers and users access them via the non-standard interfaces of the resource managers or directly via the Operating System API. On a computing resource, the local resource manager, known as the local scheduler or batch scheduler, is responsible for allocating computing elements to users’ jobs, launching them and monitoring their executions. Some well-known local schedulers include Sun Grid Engine (SGE) [22], Platform Load Sharing Facility (LSF) [23], Portable Batch System (PBS)[24] and IBM Load Leveler [45]. System administrators of these systems may also deploy a resource monitoring system, such as Ganglia [46], to report resource load/failure status.
From bottom-up, the second layer, the “Connectivity” layer provides the core capabilities of the grid architecture for sharing individual resources, namely, the security infrastructure and the networking protocol. The security infrastructure is the middleware solutions to the grid security issues we mentioned before, and it is the core of the grid architecture. Currently, the standard solution is the Grid Security Infrastructure (GSI) [38], which uses public key cryptography as the basis for its functionality. The networking capabilities make use of the widely deployed standard protocols, such as HTTP, TCP/IP, etc., and recently, web service communication protocols, such as SOAP [47], also become part of this layer as the grid architecture moves to service oriented architectures [48].
The third layer, the “Resource” layer, provides interfaces for single resource sharing, which include remote computational resource access, data sharing and replication and resource monitoring and auditing. From this layer, users are able to access individual resources using standard grid interfaces. Middleware solutions in the “Resource” layer and the “Connectivity” layer address those grid issues we mentioned in the last section and provide a standard and uniform interface to build higher level services to access multiple resources collaboratively. The middlewares in these two layers serve as the software glue between the grid resources and the applications. The open source Globus Toolkit [49] is the de facto standard for providing these middlewares. We have a dedicated section next to introduce it.
While the “Resource” layer is focused on interactions with a single resource, the next layer in the architecture contains protocols and services that are not associated with any one specific resource but rather capture interactions across collections of resources [32]. For this reason, the next layer of the architecture is referred to as the “Collective” layer, the fourth layer in Figure 2.1. Typical services include resource co-allocation, application scheduling on multiple resources, application workflow execution and monitoring, data discovery and retrievals. The work described in this dissertation belongs to this layer. Software developed in this layer varies according to the application needs of the upper “Applications” layer and it is hard to provide a general solution that fits the various types of applications.
Softwares in the “Applications” layer provide an end-user environment to use a grid for domain applications, for example, a portal interface to submit computation job or transfer files from web browser; an interface or tool to develop grid applications. The middleware functionalities in this layer also depend on the requirements of applications and users, and they are developed together with services in the “Collective” layer.
To build a grid, the development and deployment of a number of middlewares are required, including those for the standard services, such as security, information, data and resource allocation services, and those services for application development, execution management, resource aggregation, and scheduling. Again, choosing which middleware to develop and/or to deploy depends on the requirements of both the applications and users, and there is no standard configuration for setting up a general-purpose grid.
The Globus Toolkit provides a fundamental enabling technology for the grid, letting people share computing power, databases, and other tools securely across corporate, institutional, and geographic boundaries without sacrificing local autonomy. It forms the basis of many on-going efforts to provide a computational grid, and is considered to be the standard infrastructure for grid computing. The Globus provides software services and libraries as a toolkit of functions for resource management, security, data management and information services. These functions may be used individually or together and we summarize them as follows:
Earlier versions of Globus (1.x, 2.x) adopted a toolkit-based approach to realizing a grid infrastructure. The latest Globus Toolkit 4 (GT4) is a major revision of this software that aims to provide Globus functionalities in the form of web services. It uses technologies such as the Simple Object Access Protocol (SOAP) [47] and Web Services Description Language (WSDL) [52] to enable the creation, management and discovery of grid resources as web service instances.
Grid systems are interconnected collections of heterogeneous and geographically distributed resources harnessed together to satisfy the different needs of grid users. One of the biggest issues in grid systems is how to schedule users’ jobs or tasks onto multiple grid resources to achieve some performance goal(s), such as minimizing execution time, minimizing communication delays, maximizing resource utilization and/or load balancing [53]. From a system’s point of view, this distribution choice becomes a resource management problem, which is the process of identifying requirements, matching resources to applications, allocating those resources, and scheduling and monitoring grid resources over time in order to run grid applications as efficiently as possible [54].
In a grid environment, an end user submits to the grid resource management system (RMS), a grid scheduler in another term, a job to be executed along with some constraints like job execution deadline, or the maximum cost of execution. The function of the RMS is to take the job specification and from it estimate the resource requirements like the number of processors required, the execution time, and memory required. After estimating the resource requirements, RMS is responsible for discovering available resources and selecting appropriate resources for job execution, and finally schedules the job on these resources by interacting with the local resource management systems. This process makes decisions about two things: what resource(s) should be allocated for the job; and when the job should be launched on the allocated resource(s). Different scheduling policies and algorithms are applied during these two stages depending on the characteristics of the job, for example, a job with higher priority is considered earlier than lower-priority jobs.
In traditional computing systems, resource management is a well-studied problem. Resource managers such as batch schedulers, workflow engines, and operating systems exist for many computing environments. These resource management systems are designed and operate under the assumption that they have complete control of a resource and thus can implement the mechanisms and policies needed for effective use of that resource in isolation [54]. Unfortunately, this assumption does not apply to the grid and there are mainly two issues that complicate the development of a grid scheduling system.
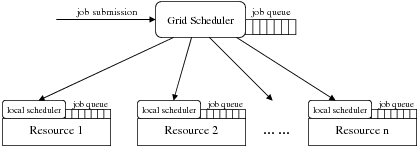
A grid scheduler works on top of multiple local schedulers and the scheduling process is much more complex than in a local scheduler as grid scheduling makes resource allocation decisions involving resources over multiple administrative domains. We refer to this as the grid scheduling hierarchy (see Figure 2.2) and a grid scheduler as a grid metascheduler [55]. A grid scheduler discovers, evaluates and co-allocates resources for grid jobs, and coordinates activities between multiple heterogeneous schedulers that operate at local or cluster level. According to this definition, a grid scheduler has two main capabilities: the scheduling capability that allows it to co-allocate resources for applications requiring collaboration between multiple sites, and the meta capability to negotiate with local schedulers to satisfy global grid requests.
One of the primary differences between a grid scheduler and a local scheduler is that the grid scheduler does not own the resources and therefore does not have control over them. The grid scheduler must negotiate with the local schedulers to request the resources that become available locally. Furthermore, the grid scheduler does not have control over the set of jobs submitted to it, or even know about the jobs being sent to the resources it is considering to use, so decisions that trade-off one jobs access for anothers cannot be made in the global sense. This lack of ownership and control causes the grid RMS not able to fully apply its resource management authority. Instead, it acts mainly as a coordinator between multiple local schedulers to make sure that the overall system performances are maintained at a level that is satisfied by users, while respecting the local policies of the resources.