offloading API overview
When an OpenMP program starts on the host device, if it encounters a target construct the target region is executed on the target device and the thread on the host waits until the execution of the thread on the device completes. In case of the target absence, the target region is also executed by the host device. In C, the target region in the code simply is created by adding the syntax bellow before the region:
#pragma omp target [clause[ [,] clause] ... ] new-line
The figure bellow shows how thread for host and devices are created for OpenMP accelerator.
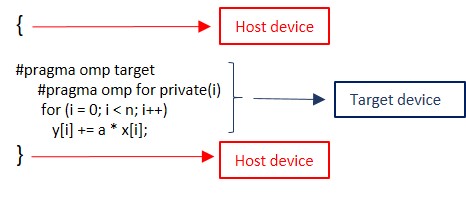
Here you can find the Example.1 for OpenMP offloading.
In this example target data map and map clauses are used which we will discuss later in this tutorial.In order to run the first example you can use this Makefile.
B. Clauses- device clause
In target construct we can define specific target device by adding device clause. If device clause is not added in the syntax the default device is considered as a target device (as it is done in example.1).
#pragma omp target device (0)
Example.2:
#pragma omp target device (0)
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += a * x[i];
Now, If the device (0) is MIC, you can use Intel compiler to compile the example as it is shown bellow and it uses in Makefile for Example1.
icc -O0 -openmp example2_offload.c -o example_off
- map clause
Using data-mapping attribute clause explicitly maps the original variables on the host device to corresponding variables in a target device data environment.
#pragma target map(to:x[0:n]) map(from:y[0:n])
The to map indicates at the start of target region the variables with to map type are initialized with the values of the original values on the host devices.
The from type indicates at the start of the target region the from map type is not initialized with the original value, but at the end of the target region these variables are assigned to the original variables on the host device.
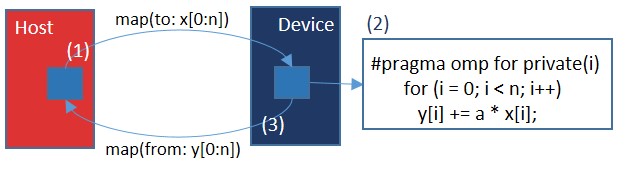
Example.3:
#pragma omp target map(to:x[0:n]) map(from:y[0:n])
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += a * x[i];
#pragma omp target if(n>THRESHOLD) map(from: p[0:N])
Example.4:
{
#pragma omp target if(n>THRESHOLD) map(to:x[0:n], z[0:n])
#pragma omp parallel for
for (i=0; i<n; i++)
y[i] = x[i] * z[i]
}
Example.5:
for (c=0; c<n; c+=CHUNKSZ)
{
#pragma omp target update to(x[c:CHUNKSZ])
#pragma omp task shared(x,y)
#pragma omp target
#pragma omp parallel for
for (i = 0; i < CHUNKSZ; i++)
y[i] += a*x[i];
#pragma omp target update from(y[0:n])
}
#pragma omp taskwait
The runnable version of this example is available here.
nowait and depend clauses were added to the target construct in OpenMP 4.5 to improve support for asynchronous execution of target regions.- nowait clause: When a thread encounters the nowait clause indicates that it would not wait for the target region, and the thread of the target task can perform other work while waiting for the target region execution to complete.
Example.6:
#pragma omp target map(to: x[0:n])map(from:y[0:n]) nowait
{
int i;
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += a * x[i];
}
The code of this example is available here.
-depend clause: The depend clause can be used for the synchronize with other tasks. In the following example different flow dependencies are used. In the first two dependencies the target task does not execute until the preceding explicit tasks have finished. The last dependence is produced in the target task. The last task does not execute until the target task finishes.Example.7:
#pragma omp parallel num_threads(2)
{
#pragma omp single
{
#pragma omp task depend(out:v1)
init(v1,n);
#pragma omp task depend(out:v2)
init(v2,n);
#pragma omp target nowait depend(in:v1,v2) depend(out:y)\
map(to:v1,v2) map(from:y)
#pragma omp parallel for private(i)
for (i = 0; i < n; i++)
y[i] += v1[i] * v2[i];
#pragma omp task depend(in:p)
output(p, N);
}
}
This example is available here for download.
Target data construct creates a new device data environment and maps the variables listed in map clause to the new device data environment. The target construct that is closed in the target data region also creates a new device data environment and inherits the variables from the target data map.
#pragma omp target data clause[ [ [,] clause] ... ] new-line
Example.8:
#pragma omp target data map(to:x[0:n],k[0:n]) map(from:y[0:n], z[0:n])
{ int i;
#pragma omp target
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += a * x[i];
#pragma omp target
#pragma omp for private(i)
for (i = 0; i < n; i++)
z[i] += a * k[i];
}
#pragma omp target data if(N>THRESHOLD) map(from: p[0:N])
Example.9:
#pragma omp target data if(n>THRESHOLD) map(from: y[0:n])
{
int i;
#pragma omp target if (n>THRESHOLD) map (to: x[0:n], z[0:n])
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += z[i] * x[i];
}
This example can be downloaded from this link.
- enter and exit clause
#pragma omp target enter data map(alloc:x[0:len])
#pragma omp target exit data map(alloc:x[0:len])
Example.10:
void init_matrix( int n, double v[])
{
#pragma omp target enter data map(alloc:v[0:n])
}
void free_matrix(int n, double v[])
{
#pragma omp target exit data map(delete:v[0:n])
}
This example can be downloaded from this link.
Update construct uses to synchronize the value of mapped variables. It uses to maintain consistency between the original values on the host device and the corresponding data in the target device.
#pragma omp target update clause[ [ [,] clause] ... ] new-line
Example.11 is available here for download.
Example.11:
#pragma omp target data map(to:v1[0:n],v2[0:n]) map(from:y[0:n])
{
#pragma omp target
#pragma omp parallel for private(i)
for (i = 0; i < n; i++)
y[i] += v1[i] * v2[i];
init(v1,n);
#pragma omp target update to (v1[0:n])
#pragma omp target
#pragma omp parallel for private(i)
for (i = 0; i< n; i++)
y[i] += v1[i] * a;
}
- if clause
-
When if clause is used with update construct, the update is happened only if the condition is met.
#pragma omp target update if (changed) to(v1[:N])
Example.12:
#pragma omp target data map(to:v1[0:n],v2[0:n]) map(from:y[0:n],y1[0:n])
{
#pragma omp target
#pragma omp parallel for
for (i = 0; i < n; i++)
y[i] += v1[i] * v2[i];
bool changed=change(v1,n);
#pragma omp target update if (changed) to (v1[0:n])
#pragma omp target
#pragma omp parallel for
for (i = 0; i < n; i++)
y1[i] += v1[i] * a;
}
This example is available here for download.
- Array section: In map clause of target and target data map a part of array can be used, however two separate sections of the same array can not be used inside of a target construct unless the second part be a subset of the first section. Example below show the valid usage of the array section.Example.13 is available here for download.
Example.13:
void foo ()
{
int A[30], *p;
#pragma omp target data map( A[0:10] )
{
p = &A[0];
#pragma omp target map( p[3:7] )
{
A[2] = 0;
p[8] = 0;
A[8] = 1;
}
}
}
Declare construct is used for two purposes: First, it can indicate the global variables and map that variables to the device data environment for the whole program. Second, it can be used with the aim of preparing a function for a target device. So, that function can be invoked in the target device as well as the host device.
#pragma omp declare target new-line
declaration-definition-seq
#pragma omp end declare target new-line
Example.14 is available here for download.
Example.14:
#pragma omp declare target
float x[N], y[N];
#pragma omp end declare target
#pragma omp target
#pragma omp for private(i)
for (i = 0; i < n; i++)
y[i] += a * x[i];
Example.15 is available here for download.
Example.15:
#pragma omp declare target
double pfun(int i, double v1[], int a)
{
return a*v1[i];
}
#pragma omp target update to(x[0:n])
#pragma omp target
#pragma omp parallel for
for (i = 0; i < n; i++)
y[i]+= F(x[i]);
#pragma omp target update from(y[0:n])
#pragma omp declare target link(sp,sv1,sv2)
Example.16:
#pragma omp declare target link(x,y)
double x[n], y[n], z[n];
#pragma omp end declare target
#pragma omp target update to(x)
#pragma omp target
#pragma omp parallel for
for (i = 0; i < n; i++)
y[i] += a * x[i];
#pragma omp target update from (y)
This example can be downloaded here.
#pragma omp declare simd uniform(i) linear(k) notinbranch
Example.17 can be download from this link.
Example.17:
#pragma omp declare target
#pragma omp declare simd uniform(i) linear(j) notinbranch
double pfun( int i, int j, double v1[n][n])
{
return a * v1[i][j];
}
#pragma omp end declare target
int main(int argc, char* argv[])
{
#pragma omp target map(tofrom:tmp) map(to: v1[0:n][0:n])
{
#pragma omp parallel for reduction(+:tmp)
for (i=0; i<n;i++)
{
double tmp1=0;
#pragma omp simd reduction(+:tmp1)
for (k=0;k<n; k++)
tmp1+= pfun(i,k,v1);
}
}
}
#pragma omp teams [clause[ [,] clause] ... ] new-line
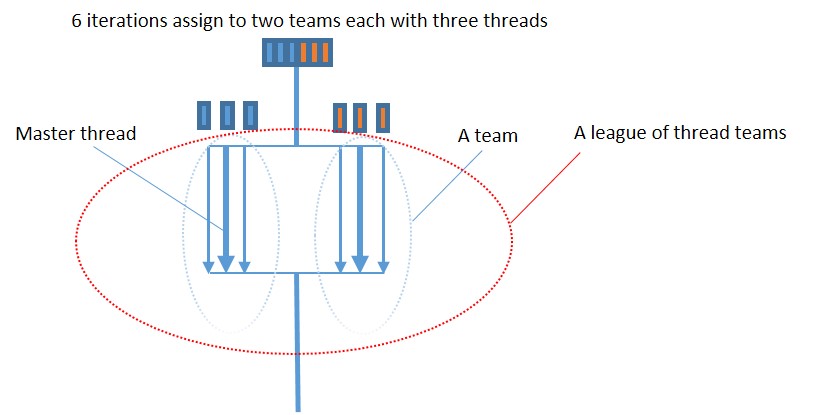
B. Clauses
Example.18:
float dotprod(float B[], float C[], int N)
{
float sum0 = 0.0;
float sum1 = 0.0;
#pragma omp target map(to: B[:N], C[:N]) map(tofrom: sum0, sum1)
#pragma omp teams num_teams(2)
{
int i;
if (omp_get_num_teams() != 2)
abort();
if (omp_get_team_num() == 0)
{
#pragma omp parallel for reduction(+:sum0)
for (i=0; i< N/2; i++)
sum0 += B[i] * C[i];
}
else if (omp_get_team_num() == 1)
{
#pragma omp parallel for reduction(+:sum1)
for (i=N/2; i <N; i++)
sum1 += B[i] * C[i];
}
}
return sum0 + sum1;
}
Example.19:
int block_size,int block_threads;
#pragma omp target map(to: B[0:N], C[0:N]) map(tofrom: sum)
#pragma omp teams num_teams(2) thread_limit(block_threads) reduction(+:sum)
The runnable version of this code is available here.
C. Team Construct Restrictions
1. With tread construct only distribute, parallel, parallel for, parallel sections construct can be used in the the team region. 2. A teams construct must be located within a target construct that must not have any directives or statements outside this teams construct.
#pragma omp distribute [clause[ [,] clause] ... ] new-line
Example.20:
#pragma omp target map(to:v1[0:n]) map(tofrom:sum)
#pragma omp teams num_teams(2) thread_limit(block_threads) reduction(+:sum)
#pragma omp distribute
for (i=0;i<n;i+=block_size)
{ int c= min(i+block_size,n);
#pragma omp parallel for reduction(+:sum)
for (j=i;j<c;j++)
sum+=a*v1[j];}
}
Example.21:
#pragma omp target map(to:v1[0:n]) map(tofrom:sum)
#pragma omp teams num_teams(8) thread_limit(16) reduction(+:sum)
#pragma omp distribute parallel for reduction(+:sum) dist_schedule(static, 1024) schedule(static,64)
for (i=0;i<n;i++)
sum+=a*v1[i];
This code is available here for download.
Example.22:
#pragma omp target teams map(to:v1[0:n]) map(tofrom:sum)
#pragma omp distribute simd
for (i=0;i<n;i++)
sum+=a*v1[i];
This code is available here for download.
Distribute parallel loop simd Construct also schedules the loop iterations across the master thread of each team. It vectorizes the loop that follows worksharing. Example.23 is the example for this construct and can be downloaded from this link.
Example.23:
#pragma omp target teams map(to:v1[0:n]) map(tofrom:sum)
#pragma omp distribute parallel for simd
for (i=0;i<n;i++)
sum+=a*v1[i];
Combined constructs are a shortcut way to specify one construct inside another construct. The Composite constructs of distribute and team constructs with other constructs are also defined by OpenMP 4.0. Here is the list and syntax of the composite constructs:
- Distribute simd
#pragma omp distribute simd [clause[ [,] clause] ... ] newline
for-loops
#pragma omp distribute parallel for [clause[ [,] clause] ... ] newline
for-loops
#pragma omp distribute parallel for simd [clause[ [,] clause] ... ] newline
for-loops
#pragma omp teams distribute parallel for [clause[ [,] clause] ... ] new-line
for-loops
#pragma omp target teams distribute parallel for [clause[ [,] clause] ... ] new-line
for-loops
here you can find an example for the combined constructs of team and distribute.
Example.24:
void get_dev_cos(double *mem, size_t s)
{
int h, t, i;
double * mem_dev_cpy;
h = omp_get_initial_device();
t = omp_get_default_device();
if (omp_get_num_devices() < 1 || t < 0) {
printf(" ERROR: No device found.\n");
exit(1);
}
mem_dev_cpy = omp_target_alloc( sizeof(double) * s, t);
if(mem_dev_cpy == NULL){
printf(" ERROR: No space left on device.\n");
exit(1);
}
/* dst src */
omp_target_memcpy(mem_dev_cpy, mem, sizeof(double)*s, 0, 0, t, h);
#pragma omp target is_device_ptr(mem_dev_cpy) device(t)
#pragma omp teams distribute parallel for
for(i=0;i<s;i++){ mem_dev_cpy[i] = cos((double)i); } /* init data */
/* dst src */
omp_target_memcpy(mem, mem_dev_cpy, sizeof(double)*s, 0, 0,S-36 h, t);
omp_target_free(mem_dev_cpy, t);